고정 헤더 영역
상세 컨텐츠
본문
728x90
# NVL / NVL2 함수
| NVL | 첫 번째 매개변수가 NULL인 경우 두 번째 매개변수를 반환 | NVL(expr1, expr2) | NVL(emp_name, '이름 없음') |
| NVL2 | 첫 번째 매개변수가 NULL이 아닌 경우 두 번째 매개변수를 반환, NULL인 경우 세 번째 매개변수를 반환 | NVL2(expr1, expr2, expr3) | NVL2(emp_name, '이름 있음', '이름 없음') |
- NVL 함수 예제:
- NVL(emp_name, '이름 없음'): emp_name이 NULL일 경우 '이름 없음'을 반환.
- NVL2 함수 예제:
- NVL2(emp_name, '이름 있음', '이름 없음'): emp_name이 NULL이 아니면 '이름 있음'을 반환, NULL이면 '이름 없음'을 반환.
-- NULL 값이 존재할 때 1로 치환하여 곱한 결과를 출력 : NVL
SELECT salary * NVL(commission_pct, 1)
FROM employees
ORDER BY commission_pct;
-- NVL2 (A, B, C) A가 NULL 이면 C를 그대로 출력, A가 NULL이 아니면 B와 C를 곱해서 출력
SELECT
FIRST_NAME,
LAST_NAME,
SALARY,
COMMISSION_PCT,
NVL2(COMMISSION_PCT, SALARY * (1 + COMMISSION_PCT), SALARY) AS TOTAL_COMPENSATION
FROM EMPLOYEES;
# DECODE 함수
| DECODE | 첫 번째 매개변수와 일치하는 경우 두 번째 매개변수를 반환, 그렇지 않으면 세 번째 매개변수를 반환 | DECODE(expr, search1, result1, [search2, result2, ...], default) | DECODE(department_id, 10, 'IT', 20, 'HR', 'Other') |
- DECODE 함수 설명:
- DECODE 함수는 첫 번째 매개변수와 다음 매개변수 쌍들을 비교하여 일치하는 경우 해당 결과를 반환합니다. 일치하는 값이 없을 경우 옵션으로 지정한 기본값을 반환
- 첫 번째 매개변수(expr): 비교할 값
- search1, search2, ...: 비교할 값들
- result1, result2, ...: 일치할 때 반환할 값들
- default (선택적): 모든 검색 값이 일치하지 않을 때 반환할 기본 값
- DECODE 함수 예제:
- DECODE(department_id, 10, 'IT', 20, 'HR', 'Other'): department_id가 10이면 'IT', 20이면 'HR', 그 외의 값은 'Other'를 반환
-- DECODE (A, B, C, D) A가 B인 경우 C값을 반영 A가 B가 아니면 D값 그대로 출력
SELECT FIRST_NAME,
LAST_NAME,
DEPARTMENT_ID,
SALARY AS 원래급여,
DECODE(DEPARTMENT_ID, 60, SALARY*1.1, SALARY) AS 조정된급여,
DECODE(DEPARTMENT_ID, 60, '10%인상', '미인상') AS 인상여부
FROM EMPLOYEES;
SELECT FIRST_NAME,
LAST_NAME,
DEPARTMENT_ID,
SALARY AS 원래급여,
DECODE(DEPARTMENT_ID,
10, '과학',
100, '수학',
110, '영어',
'기타') AS 과목명
FROM EMPLOYEES;# CASE / WHEN / THEN 함수
| CASE | 조건에 따라 다른 결과를 반환 | CASE WHEN 조건 THEN 결과 ELSE 기본값 END |
| WHEN | CASE 문에서 특정 조건을 설정 | WHEN SALARY >= 9000 THEN '상위급여' |
| THEN | WHEN 절에서 조건이 참일 때 반환할 결과를 지정 | THEN '중위급여' BETWEEN AND 1000 사용 조회 END |
-- CASE / WHEN / THEN 함수
SELECT EMPLOYEE_ID, FIRST_NAME, LAST_NAME, SALARY,
CASE
WHEN SALARY >= 9000 THEN '상위급여'
WHEN SALARY BETWEEN 6000 AND 8999 THEN '중위급여'
ELSE '하위급여'
END AS 급여등급
FROM EMPLOYEES
WHERE JOB_ID = 'IT_PROG';
# RANK , DENSE_RANK, ROW_NUMBER 함수
| RANK | 순위를 계산하며, 동일 순위가 있을 경우 같은 순위를 가지고 다음 순위는 건너뜀 | RANK() OVER (PARTITION BY partition_expr ORDER BY order_expr) | RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) |
| DENSE_RANK | 순위를 계산하며, 동일 순위가 있을 경우 같은 순위를 가지지만 다음 순위는 건너뛰지 않음 | DENSE_RANK() OVER (PARTITION BY partition_expr ORDER BY order_expr) | DENSE_RANK() OVER (ORDER BY salary DESC) |
| ROW_NUMBER | 각 행에 순차적인 번호를 부여 | ROW_NUMBER() OVER (PARTITION BY partition_expr ORDER BY order_expr) | ROW_NUMBER() OVER (ORDER BY hire_date) |
- RANK: 정렬된 결과에서 각 행의 순위를 부여하며, 동일한 순위를 가질 수 있고 그 다음 순위는 건너뜀
- DENSE_RANK: 정렬된 결과에서 각 행의 순위를 부여하며, 동일한 순위를 가질 수 있고 그 다음 순위를 건너뛰지 않음
- ROW_NUMBER: 정렬된 결과에서 각 행에 순차적인 번호를 부여합니다. 동일한 값이 있어도 각 행에 대해 고유한 번호를 부여
각 함수는 OVER 절과 함께 사용
분석 함수로서, 특히 순위를 계산하거나 행에 번호를 할당할 때 유용하게 사용
-- RANK , DENSE_RANK, ROW_NUMBER 함수
SELECT EMPLOYEE_ID, SALARY,
RANK( ) OVER(ORDER BY SALARY DESC) RANK_급여,
DENSE_RANK( ) OVER(ORDER BY SALARY DESC) DENSE_RANK_급여,
ROW_NUMBER( ) OVER(ORDER BY SALARY DESC) ROW_NUMBER_급여
FROM EMPLOYEES;
SELECT
E.EMPLOYEE_ID,
D.DEPARTMENT_ID,
D.DEPARTMENT_NAME,
SALARY,
RANK( ) OVER(PARTITION BY D.DEPARTMENT_ID ORDER BY SALARY DESC) RANK_급여,
DENSE_RANK( ) OVER(PARTITION BY D.DEPARTMENT_ID ORDER BY SALARY DESC) DENSE_RANK_급여,
ROW_NUMBER( ) OVER(PARTITION BY D.DEPARTMENT_ID ORDER BY SALARY DESC) ROW_NUMBER_급여
FROM EMPLOYEES E, DEPARTMENTS D
WHERE D.DEPARTMENT_ID = D.DEPARTMENT_ID
ORDER BY D.DEPARTMENT_ID, E.SALARY DESC;
# 그룹함수
- 그룹함수는 단일행 함수와 달리 여러행에 대해 함수가 적용되어 하나의 결과를 나타냄
- 집계함수라고도 함
| COUNT | 지정된 열의 행 수를 반환 | COUNT(*), COUNT(column_name) |
| SUM | 지정된 열의 합을 계산 | SUM(salary) |
| AVG | 지정된 열의 평균을 계산 | AVG(salary) |
| MIN | 지정된 열의 최소값을 반환 | MIN(hire_date) |
| MAX | 지정된 열의 최대값을 반환 | MAX(hire_date) |
- COUNT: 그룹 내 행의 수를 계산합니다. COUNT(*)은 그룹 내 모든 행 수를 세고, COUNT(column_name)은 해당 열이 NULL이 아닌 행 수를 셈
- SUM: 지정된 열의 값을 모두 합산
- AVG: 지정된 열의 평균 값을 계산
- MIN: 지정된 열에서 가장 작은 값을 반환
- MAX: 지정된 열에서 가장 큰 값을 반환
-- 그룹함수
-- COUNT 함수
SELECT COUNT(SALARY) AS SALARY행수
FROM employees;
-- NULL 값이 있으면 NULL값 제외한 갯수만 출력
SELECT COUNT(COMMISSION_PCT) AS COMMISSION_PCT행수
FROM employees;
-- NULL 값까지 포함된 갯수
SELECT COUNT(*)AS COMMISSION_PCT행수
FROM employees;
-- 전체 행의 개수에서 데이터가 존재하는 행을 빼면 NULL값을 가진 행수 출력
SELECT COUNT(*) - COUNT(COMMISSION_PCT) AS COMMISSION_PCT행수
FROM employees;
-- SUM , AVG 함수
SELECT
SUM(SALARY) AS 합계,
AVG(SALARY) AS 평균,
SUM(SALARY)/COUNT(SALARY) AS 계산된평균
FROM EMPLOYEES;
-- MAX , MIN 함수
SELECT
MAX(SALARY) AS 최댓값,
MIN(SALARY) AS 최소값,
MAX(FIRST_NAME) AS 최대문자값,
MIN(FIRST_NAME) AS 최소문자값
FROM EMPLOYEES;
# GROUP BY
- 특정 컬럼을 기준으로 그룹화하여 테이블에 존재하는 행들을 그룹별로 구분하기 위해 사용
- 그룹 함수를 쓰되, 어떤 컬럼값을 기준으로 그룹 함수를 적용할지 명시해야 함
SELECT column1, aggregate_function(column2)
FROM table_name
WHERE conditions
GROUP BY column1;
GROUP BY 절의 중요성
- 데이터 요약: 대량의 데이터를 각 그룹별로 요약하여 보다 의미 있는 정보를 추출
- 집계 작업: 데이터의 합계, 평균, 최소값, 최대값 등을 계산하여 비즈니스 결정에 필요한 정보를 제공
- 효율적인 쿼리: 데이터를 그룹화하고 집계 함수를 사용하면 데이터베이스 성능을 최적화
-- GROUP BY 그룹으로 묶기
SELECT
JOB_ID AS 직무,
SUM(SALARY) AS 직무별_총급여,
AVG(SALARY) AS 직무별_평균급여
FROM employees
WHERE employee_id >= 10
GROUP BY JOB_ID
ORDER BY 직무별_총급여 DESC, 직무별_평균급여;
SELECT
JOB_ID AS JOB_ID_대그룹,
MANAGER_ID AS MANAGER_ID_중그룹,
SUM(SALARY) AS 그룹핑_총급여,
AVG(SALARY) AS 그룹핑_평균급여
FROM employees
WHERE employee_id >= 10
GROUP BY JOB_ID, MANAGER_ID
ORDER BY 그룹핑_총급여 DESC, 그룹핑_평균급여;
# HAVING
GROUP BY 절에 의해 생성된 결과 값 중 원하는 조건에 부합하는 자료만 보고자 할 때 사용
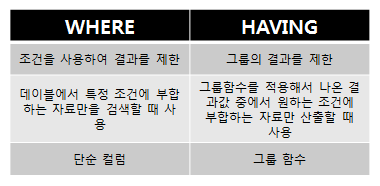
-- HAVING 연산된 그룹 함수 결과에 조건 적용
SELECT
JOB_ID AS 직무,
SUM(SALARY) AS 직무별_총급여,
AVG(SALARY) AS 직무별_평균급여
FROM employees
WHERE employee_id >= 10
GROUP BY JOB_ID
HAVING SUM(SALARY) > 30000
ORDER BY 직무별_총급여 DESC, 직무별_평균급여;
# 동등 조인 (Equi Join)
- 동등 조인은 두 개의 테이블 간에 특정 조건을 만족하는 행을 결합하는 조인 방법
- 일반적으로 이 조건은 두 테이블 간의 동등한 값을 가진 열들을 기준
| 내부 동등 조인 | 두 테이블에서 조인 조건을 만족하는 행만을 결과에 포함시키는 조인 |
| 사용 예시 | SELECT * FROM 테이블1 t1 INNER JOIN 테이블2 t2 ON t1.열 = t2.열; |
# 외부 조인 (Outer Join)
- 외부 조인은 조인 조건을 만족하지 않더라도, 한쪽 테이블의 모든 행을 결과에 포함시키는 조인 방법
- 오라클에서는 왼쪽 외부 조인, 오른쪽 외부 조인, 그리고 전체 외부 조인(풀 아웃터 조인)을 지원
| 왼쪽 외부 조인 | 왼쪽 테이블의 모든 행을 결과에 포함시키고, 조인 조건을 만족하는 오른쪽 테이블의 행을 포함 |
| 사용 예시 | SELECT * FROM 테이블1 t1 LEFT OUTER JOIN 테이블2 t2 ON t1.열 = t2.열; |
| 오른쪽 외부 조인 | 오른쪽 테이블의 모든 행을 결과에 포함시키고, 조인 조건을 만족하는 왼쪽 테이블의 행을 포함 |
| 사용 예시 | SELECT * FROM 테이블1 t1 RIGHT OUTER JOIN 테이블2 t2 ON t1.열 = t2.열; |
| 전체 외부 조인 | 양쪽 테이블의 모든 행을 결과에 포함시킵니다. 한쪽 테이블에 없는 경우 NULL로 채워짐 |
| 사용 예시 | SELECT * FROM 테이블1 t1 FULL OUTER JOIN 테이블2 t2 ON t1.열 = t2.열; |
# 자체 조인 (Self Join)
- 자체 조인은 같은 테이블 내에서 조인을 수행하는 것을 의미
- 동일한 테이블에서 서로 다른 행을 조인하여 데이터를 추출하는 경우에 사용
| 기본 자체 조인 | 같은 테이블에서 조인 조건을 만족하는 서로 다른 행을 연결하는 경우입니다. |
| 사용 예시 | SELECT e1.employee_id, e1.manager_id, e2.employee_id AS manager_id FROM employees e1, employees e2 WHERE e1.manager_id = e2.employee_id; |
-- 동등조인 : 똑같은 데이터끼리 연결
SELECT *
FROM EMPLOYEES A, DEPARTMENTS B
WHERE A.DEPARTMENT_ID = B.DEPARTMENT_ID;
-- EMPLOYEES, DEPARTMENTS, locations 테이블 간에 조인하여 조건을 만족하는 데이터 선택
SELECT A.EMPLOYEE_ID, A.DEPARTMENT_ID, B.DEPARTMENT_NAME, C.LOCATION_ID, C.CITY
FROM EMPLOYEES A, DEPARTMENTS B, LOCATIONS C
WHERE A.DEPARTMENT_ID = B.DEPARTMENT_ID
AND B.LOCATION_ID = C.LOCATION_ID;
-- 외부조인 : 모든 데이터 연결
-- 모든 EMPLOYEES과 DEPARTMENTS 데이터를 연결
SELECT COUNT(*) AS 조인된건수
FROM EMPLOYEES A, DEPARTMENTS B
WHERE A.DEPARTMENT_ID = B.DEPARTMENT_ID;
-- 데이터가 부족한 쪽에 + 기호를 명시해야 함
-- EMPLOYEES와 DEPARTMENTS 테이블을 외부조인하되, DEPARTMENTS에 데이터가 없는 경우도 포함
SELECT A.EMPLOYEE_ID, A.FIRST_NAME, A.LAST_NAME, B.DEPARTMENT_ID, B.DEPARTMENT_NAME
FROM EMPLOYEES A, DEPARTMENTS B
WHERE A.DEPARTMENT_ID = B.DEPARTMENT_ID(+)
ORDER BY A.EMPLOYEE_ID;
-- + 기호 반대로 명시
SELECT A.EMPLOYEE_ID, A.FIRST_NAME, A.LAST_NAME, B.DEPARTMENT_ID, B.DEPARTMENT_NAME
FROM EMPLOYEES A, DEPARTMENTS B
WHERE A.DEPARTMENT_ID(+) = B.DEPARTMENT_ID
ORDER BY A.EMPLOYEE_ID;
-- 자체조인 : 자기자신의 데이터와 연결
SELECT A.EMPLOYEE_ID, A.FIRST_NAME, A.LAST_NAME, A.MANAGER_ID,
B.FIRST_NAME||' '||B.LAST_NAME AS MANAGER_NAME
FROM EMPLOYEES A, EMPLOYEES B
WHERE A.MANAGER_ID = B.EMPLOYEE_ID
ORDER BY A.EMPLOYEE_ID;
-- 집합연산자 : 집합으로 연결
-- 합쳐서 하나로 출력, 중복된것은 제외
SELECT DEPARTMENT_ID
FROM EMPLOYEES
UNION
SELECT DEPARTMENT_ID
FROM DEPARTMENTS;
-- 합쳐서 하나로 출력, 중복된것 포함
SELECT DEPARTMENT_ID
FROM EMPLOYEES
UNION ALL
SELECT DEPARTMENT_ID
FROM DEPARTMENTS
ORDER BY DEPARTMENT_ID;
-- 겹치는 것만 출력
SELECT DEPARTMENT_ID
FROM EMPLOYEES
INTERSECT
SELECT DEPARTMENT_ID
FROM DEPARTMENTS
ORDER BY DEPARTMENT_ID;
-- 겹치는것 빼고 출력 MINUS
SELECT DEPARTMENT_ID
FROM DEPARTMENTS
MINUS
SELECT DEPARTMENT_ID
FROM EMPLOYEES;
SELECT
E.FIRST_NAME,
E.LAST_NAME,
D.DEPARTMENT_NAME
FROM EMPLOYEES E
JOIN DEPARTMENTS D ON E.DEPARTMENT_ID = D.DEPARTMENT_ID;
'CLASS_SQL' 카테고리의 다른 글
| 6월 28일_SQL(VIEW, JAVA에서 SQL불러오기) (0) | 2024.06.28 |
|---|---|
| 6월 27일_SQL(데이터의 무결성, 제약조건) (0) | 2024.06.27 |
| 6월 26일_SQL(서브쿼리문, 다중행연산자, DML, DDL) (0) | 2024.06.26 |
| 6월 24일_SQL(WHERE조건절, 연산자, 문자, 숫자, 날짜 함수) (0) | 2024.06.24 |
| 6월 21일_SQL(기초, 오라클 사용, SELECT 구문) (0) | 2024.06.21 |




